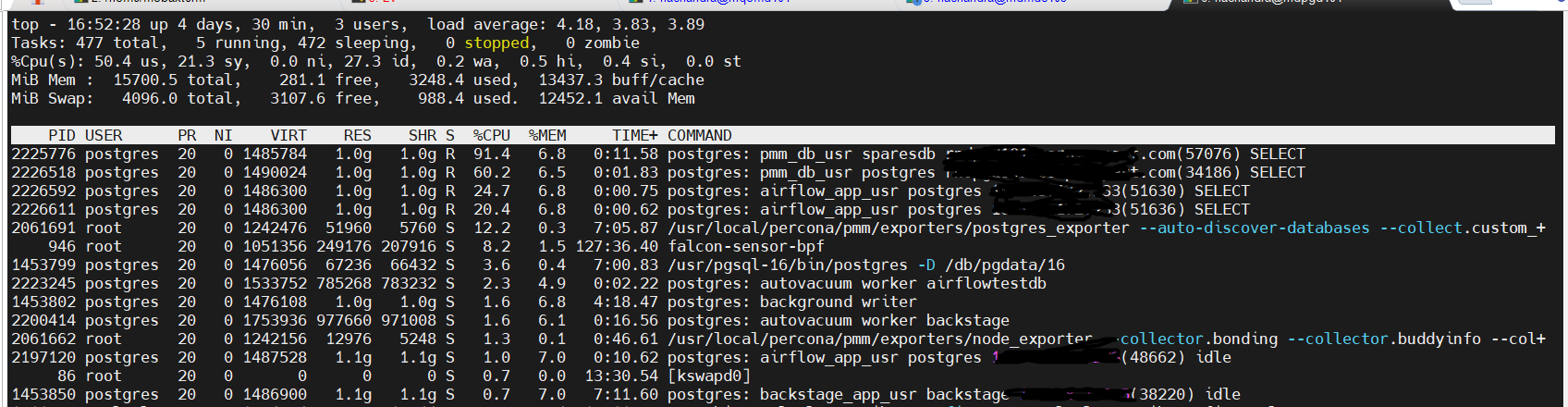
PMM agent queries are consuming high CPU, and I’m not sure why they are taking this much processing power. Can someone help me understand why these queries are continuously using high CPU on each database one after another?
PMM Server version: 3.2.0
Hi Naresh,
To continue the investigation, I’d suggest you to use those PIDs to see the exact query being executed. For instance, for the first client you showed, get the PID from the first top column and use it in a query like:
postgres=# SELECT * FROM pg_stat_activity WHERE pid = 2225776;
Those outputs will show you the exact query text (under the query column), and you can then check which PMM client functionality is behind running it.
Hi @Agustin_G
Here are the details for the PID.
postgres=# SELECT * FROM pg_stat_activity WHERE pid = 3516805;rtestd101.corp.test.com
Time: 1.584 ms
postgres=# SELECT * FROM pg_stat_activity WHERE pid = 3522354;rtestd101.corp.test.com
Time: 2.034 ms
Hi @Agustin_G
I can continuously see the two queries below when I check based on the PIDs.
SELECT
SELECT current_database() datname, schemaname, relname, heap_blks_read, heap_blks_hit, idx_blks_read, idx_blks_hit, toast_blks_read, toast_blks_hit, tidx_blks_read, tidx_blks_hit FROM pg_statio_user_tables;
nurlan
November 19, 2025, 12:04pm
7
Hi Naresh, seems like you have a lot of tables which creates huge response and my recommendation would be to remove these queries from custom queries list.
Hi @nurlan
Thanks for the reply.
Is there any alternative solution for this issue? Otherwise, we will lose the monitoring, right?